ASTER
- Is there a fee associated with ordering ASTER data?
- What ASTER data products require an order to be placed?
- Can anyone submit a request to acquire new ASTER data over a specific location?
- Why are the corners clipped for some AST_L1T VNIR only scenes?
- Why is there not an AST_L1T scene for every AST_L1A granule?
- How can I tell if a scene is terrain or precision corrected?
- What is the difference between terrain and precision correction?
- What is the difference between ASTER GDEM Versions 1, 2 and 3?
- Does ASTGTM V3 have special policy agreements similar to V2?
- What files do you get when you request HDF-EOS or GeoTiff?
- What software can be used with ASTER?
- What ASTER data would be best to use for mineral research?
- Why was radiometric calibration coefficients (RCC) updated from Version 4 to 5 and applied to the entire ASTER line of products?
- What is the difference between ASTER L1T V003 and ASTER L1T V031?
ECOSTRESS
- Why are there no ECOSTRESS observations over my specific study site?
- Why are there Level 1B ECOSTRESS observations over my specific study site, but not matching higher-level observations over my specific site?
- Why are there gaps in the observation record?
- Why are some of my Level 1B Radiance observations missing bands 1 and 3?
- Why do I see striping artifacts in the ECOSTRESS data--even after projecting the swath data to a grid?
- Why are there small patches of missing data?
- Sometimes there are obstructions in the image, what is this?
- Can I use ECO1BGEO files with corresponding Level 1B - Level 4 files if the build ID and/or product version number differ?
- Why do some waterbodies appear to be warmer than land?
EMIT
- What is imaging spectroscopy?
- Why are there no EMIT observations over my specific study site?
- Why are there gaps in the EMIT observation record?
- How do I orthorectify EMIT data granules?
- How does the EMIT mission support Open Science?
- Other than mineral mapping, what applications does EMIT data have?
- Why are there black rectangular segments that stretch across some scenes?
- Why are there obstructions blocking some images?
GEDI
- Why do GEDI elevation values over my region of interest not match elevation values from another digital elevation model (DEM)?
- How are GEDI beams split and dithered and what do these two terms mean?
- How should I quality filter GEDI L1B - L2B data?
- How do I subset GEDI data spatially and by band/layer?
- How do I cite the data?
- What science datasets does the GEDI Geolocated Waveforms product contain?
- What science datasets does the GEDI Level 2A product contain?
- What science datasets does the Global Ecosystem Dynamics Investigation Level 2B product contain?
- Why is the uneven spacing between beams across track?
- How do I extract elevation and height metrics for alternative algorithm setting groups in L2A?
- How do I extract cover and vertical profile metrics for alternative algorithm setting groups in L2B?
- In L2A, why are Relative Height (RH) values sometimes negative?
- Is GEDI still an active instrument?
- What format does GEDI data come in?
- Asking additional GEDI questions?
HLS
- What is the difference between the L30 and the S30 product?
- What is the difference between the version 1.4 and 2.0 products?
- What is the difference between HLS granules and files? Also, what is a Cloud Optimized GeoTIFF (COG)?
- What are the criteria for selecting acceptable Sentinel-2 Tiles for HLSS30 v2.0 processing?
G-LiHT
- Why did NASA scientists develop G-LiHT?
- How intercomparable are G-LiHT acquisitions and data products?
- How is G-LiHT calibrated?
- How is the at-sensor reflectance product computed?
- How do I cite G-LiHT data in a paper?
- Can I request G-LiHT data acquisitions for a specific study site?
- Why do some Digital Surface Model (DSM) granules contain only three science data layers while others contain five?
- How do I view the data in the Hyperspectral datasets (GLREFL, GLRADS, GLHYVI, GLHYANC)?
Data Citation and Reuse
ASTER
Is there a fee associated with ordering ASTER data?
No. Effective April 1, 2016, all data products distributed by the LP DAAC are available for public distribution at no charge.
What ASTER data products require an order to be placed?
All ASTER data, aside from the Precision Terrain Corrected (AST_L1T) and expedited data (AST_L1AE and AST_L1BE), require an order to be placed, as the product will be made on-demand. This includes radiance data (AST_09, AST_09T, AST_09XT, AST_L1B, and AST_14OTH), elevation data (AST14DEM, AST14DMO), emissivity data (AST_05), temperature data (AST_08), reflectance data (AST_07 and AST_07XT), and unprocessed data (AST_L1A). In addition, ASTER GDEM (ASTGTM) Version 3 data can be accessed using NASA's Earthdata Search.
Can anyone submit a request to acquire new ASTER data over a specific location?
Requests for ASTER acquisitions can be submitted by approved users through the Data Acquisition Request (DAR) tool. More information on how to apply to be an approved user is available through the NASA JPL ASTER website.
Why are the corners clipped for some AST_L1T VNIR only scenes?
These clipped corners are due to errors, such as band offsets or projection of boundary data outside of the scene frame.
Why is there not an AST_L1T scene for every AST_L1A granule?
ASTER Precision Terrain Corrected scenes are not produced if any of the bands in an AST_L1A granule fail during resampling. This typically occurs due to errors in the AST_L1A geolocation arrays. Additionally, since AST_L1T scenes are processed using AST_L1B processing algorithms, AST_L1T scenes are not available when there are any band failures in an AST_L1B granule. Finally, a band in a AST_L1T scene may not be available if the telescope related to the band was not requested to be turned on during acquisition.
How can I tell if a scene is terrain or precision corrected?
This information can be found in the ASTER Precision Terrain Corrected (AST_L1T) metadata, under the field "CorrectionAchieved". This field will be populated with the level of correction (Terrain+Precision, Terrain+Systematic, Systematic, or Precision) obtained for the scene.
What is the difference between terrain and precision correction?
Terrain correction removes geometric errors associated with observing a ground location from an off-nadir angle. AST_L1T scenes that do not have Digital Elevation Model (DEM) available will not have terrain correction. These scenes are typically over open ocean and small islands. Precision correction removes the geometric errors due to imprecise knowledge of the satellite's location and velocity (or ephemeris), its behavior (yaw, pitch, or roll), and the detector acquisition information. Precision correction is completed when 20 or more ground reference points can be matched to an equivalent region in an ASTER Precision Terrain Corrected (AST_L1T) scene. If these locations cannot be matched, the scene will not be precision corrected. This may be due to clouds in the region, a dark scene (potentially a scene captured at night), the angle of the sun and shadows in the scene, or the scene is a thermal infrared (TIR) scene. If a scene is not precision terrain corrected, it will have systematic correction, similar to a north-up AST_L1B scene. For more information please read the AST_L1T Quick Guide.
What is the difference between ASTER GDEM Versions 1, 2 and 3?
ASTER GDEM Version 1, released in June 2009, was generated using stereo-pair images collected by the ASTER instrument aboard Terra. ASTER GDEM coverage spans from 83 degrees north latitude to 83 degrees south, encompassing 99 percent of Earth's landmass and comprising 16,602 1° by 1° tiles.
Version 2 added 260,000 stereo-pairs, improving coverage and reducing the occurrence of artifacts. The refined production algorithm provided improved spatial resolution, increased horizontal and vertical accuracy, and superior water body coverage and detection. It comprises 16,704 tiles.
Version 3 added another 360,000 stereo-pairs and comprises 22,912 tiles. Compared to Version 2, Version 3 has fewer void areas due to the increase of ASTER stereo image data and new processes, and a decrease in water area anomaly data due to the incorporation of new global water body data. With this release, an additional global product is now available: the ASTER Water Body Database (ASTWBD). This raster product identifies all water bodies as either ocean, river, or lake. Each GDEM tile has a corresponding ASTERWBD tile, which can be used as a water bodies mask.
Does ASTGTM V3 have special policy agreements similar to V2?
ASTGTM V3 does not have restrictions on reuse, sale, or redistribution. Please see the data citations and policies at https://lpdaac.usgs.gov/data/data-citation-and-policies/.
What files do you get when you request HDF-EOS or GeoTiff?
With GeoTiff (.tif) as an output file format, there are multiple files associated with one granule; therefore, the file is compressed. The compressed file contains a GeoTiff file for each band as well as GeoTiffs for metadata and ancillary data files. The HDF-EOS file contains all the band information and ancillary data in one file.
What software can be used with ASTER?
A number of applications and software packages can be used to work with ASTER data. A list of potential resources can be found on ASTER Tools and Services.
What ASTER data would be best to use for mineral research?
Some minerals have distinctive shortwave infrared spectral signatures while others have unique thermal infrared emissivity spectral signatures. Therefore, ASTER Level 2 data products (AST_05, AST_07, AST_07XT, AST_08, AST_09, and AST_09XT) are suitable for mineral research. However, it is highly recommended that users perform additional research on their own for their mineral of interest.
Why was radiometric calibration coefficients (RCC) updated from Version 4 to 5 and applied to the entire ASTER line of products?
Since 2000, radiometric corrections derived from onboard calibrator degradation curves have been applied to L1A processing to offset sensor degradation, which can occur naturally as sensors degrade over time while in orbit. Radiometric calibration coefficients (RCC) Versions 1 – 3 relied primarily on the degradation curves from the onboard calibrator. However, studies have found that degradation curves from the onboard calibration were inconsistent against vicarious and cross calibrations. In 2014, the ASTER Science Team combined results of degradation curves from onboard calibration, vicarious calibration and cross calibration approaches to derive radiometric corrections, known as V4; however, inter-band and band traceability inconsistencies have been observed based on other calibration approaches (inter-band and lunar calibrations). The ASTER Science Team decided to rely on vicarious and lunar calibrations to derive degradation curves to generate radiometric corrections, which are known as RCC V5. The recent degradation curves derived from vicarious and lunar calibrations are consistent with inter-band and lunar calibrations and yield same traceability in bands. The degradation curves only affect bands from the VNIR region of the spectrum. Degradation curves for band 1 show minimal difference between RCC V4 and RCC V5 while bands 2 and both forward and backward-looking band 3 showed considerable difference. ASTER expedited products as well as ASTGTM and ASTWTB undergo separate processing route; therefore, they are not impacted by the application of the new RCC V5.
Information on the study can be found in the following document: Tsuchida, S.; Yamamoto, H.; Kouyama, T.; Obata, K.; Sakuma, F.; Tachikawa, T.; Kamei, A.; Arai, K.; Czapla-Myers, J.S.; Biggar, S.F.; Thome, K.J. Radiometric Degradation Curves for the ASTER VNIR Processing Using Vicarious and Lunar Calibrations. Remote Sens. 2020, 12, 427. https://doi.org/10.3390/rs12030427.
What is the difference between ASTER L1T V003 and ASTER L1T V031?
ASTER L1T V003 is generated from forward processing derived directly from the ASTER L1T inventory pre-processed with radiometric calibration coefficient (RCC) Version 4. The intent is to provide quick turnaround of ASTER L1T V003 to users who are interested in generating time series analysis with one consistent RCC version.
ASTER L1T V031 is generated from on-demand processing where Science Scalable Scripts-based Science Processor for Missions (S4PM) processing system is used to generate on-demand products. S4PM generates the user requested ASTER L1T V031 product with RCC V5 applied. The turnaround is dependent on the number of granules the user ordered.
MODIS
Why do I get some unexpectedly large or hard to interpret data values when I am working with MODIS data?
Most MODIS Science Data Set (SDS) layers are in 8-bit or 16-bit format. This requires a scaling factor to be applied. For information on the scale factor of a specific band for a specific product, please see the corresponding DOI landing. DOI landing pages can be access via the MODIS Products Table. More information on the scaling factor is available by watching the Part 2s of the MODIS Version 6 Data at NASA's LP DAAC videos on YouTube.
How can I interpret the MODIS Quality data layers?
The majority of the MODIS land products contain quality layers. Each layer contains a lot of information about the quality information associated with each individual pixel in the scene. To aid in file size management, this data has been packed in bit format. The LP DAAC offers several tools to aid in unpacking the bits and interpreting the quality information. The Application for Extracting and Exploring Analysis Ready Samples (AppEEARS) allows users to view and interact with quality information for a variety of products before they download the data. The ArcGIS MODIS Python Toolbox provides users with a simple and intuitive way to decode and interact with quality layers for previously downloaded MODIS products using ArcGIS. More information on interpreting the quality information and using these tools is available by watching the Part 3s of the MODIS Version 6 Data at NASA's LP DAAC on videos YouTube.
What improvements have been implemented in MODIS V6.1?
The Version 6.1 Level-1B (L1B) products have been improved by undergoing various calibration changes.
Changes include:
- The response-versus-scan angle (RVS) approach that affects reflectance bands for Aqua and Terra MODIS.
- Corrections to adjust for the optical crosstalk in Terra MODIS infrared (IR) bands.
- Corrections have been made to the Terra MODIS forward look-up table (LUT) to include an update for the period 2012 - 2017.
- A polarization correction has been applied to the L1B Reflective Solar Bands (RSB).
Details on product improvements for Version 6.1 will be provided on the Digital Object Identifier (DOI) landing page for each product. Version 6 data products will remain available and will continue with forward processing during the transition.
Why are there data gaps for MODIS acquisitions after July 7, 2023?
Data gaps or missing data have become more of a routine occurrence for Terra, Aqua, and Terra+Aqua Combined MODIS data products. On July 7, 2023, the MODIS Flight Operations Team transitioned to a new schedule and no longer attempts to recover Level 0 data if the missed contact happens after regular business hours. Once data gaps that have occurred during the Light-Out-Operations (LOOps) period from 6 pm to 6 am Eastern time have been confirmed, the data loss events will be added to the list of dates and times of the known LOOps events.
All Terra, Aqua, and Combined Terra+Aqua MODIS Version 6.1 data products are directly impacted by the non-recoverable data loss.
ECOSTRESS
Why are there no ECOSTRESS observations over my specific study site?
ECOSTRESS priority data coverage includes the lower (48) continental United States (CONUS), twelve 1,000 x 1,000 km key climate zones, and twelve Fluxnet sites.
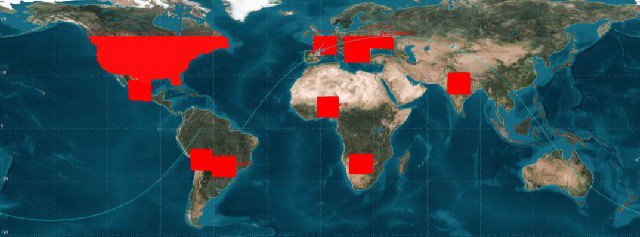
Why are there Level 1B ECOSTRESS observations over my specific study site, but not matching higher-level observations over my specific site?
There may be ECOSTRESS Level 1B observations that are acquired over your study site, but if the observation lies outside of one of the zones described above, they will not be processed into the L2-L4 products. Also, higher-level products are dependent on a suite of input variables in addition to the Level 1B radiance files. If circumstances such as cloudy observations, missing required input variables, or higher-level product model failures, this will lead to fill values or no data over your study site.
Why are there gaps in the observation record?
ECOSTRESS was launched on June 29, 2018, and moved to autonomous science operations on August 20, 2018, following a successful in-orbit checkout period. On September 29, ECOSTRESS experienced an anomaly with its primary mass storage unit (MSU). ECOSTRESS has a primary and secondary MSU (A and B). On December 5, 2018, the instrument was switched to the secondary MSU and operations resumed with initial acquisitions over Australia and wider coverage resumed on January 9, 2019. The initial anomaly was attributed to exposure to high radiation regions, primarily over the Southern Atlantic Anomaly, and the acquisition strategy was revised to exclude these regions from future acquisitions. On March 14, 2019, the secondary MSU experienced a similar anomaly temporarily halting science acquisitions. On May 15, 2019, a new direct streaming data acquisition approach was implemented, and science acquisitions resumed.
From February 8 to February 16, 2020 an ECOSTRESS instrument issue resulted in a data anomaly that created striping in band 4 (10.5 micron). This anomaly has affected ECOSTRESS Level 1B and Level 2 datasets, which include the attitude, geolocation, radiance, cloud mask, land surface temperature and emissivity data products. These data products have been removed from data access and are no longer available. Masked data are expected to be available by March 16, 2020 for all product levels. Data acquired following the anomaly have not been affected.
Why are some of my Level 1B Radiance observations missing bands 1 and 3?
In order to implement the direct streaming option, the new acquisition approach is to only download TIR data for bands 2, 4, and 5. The data products are as before, except that TIR bands 1 and 3 are not downloaded and contain fill values (in L1 radiance and L2 emissivity). All ECOSTRESS observations from May 15, 2019 to present will contain fill values in bands 1 and 3.
Why do I see striping artifacts in the ECOSTRESS data--even after projecting the swath data to a grid?
There are multiple possible reasons for striping artifacts in ECOSTRESS data acquisitions. (1) Detectors in TIR bands 1 and 5 and the SWIR band were damaged during testing, before launch. This will result in 8 lines of missing data every 128 lines in the across-track direction in those bands, and an error code of -9998 for the missing pixels. These missing pixels are filled using a neural network algorithm, but may appear as striping in cases where the prediction is not accurate. (2) ECOSTRESS is a push-whisk instrument, which means that a scene is made up of 44 scans, stacked in the along-track direction. Each of these scans has an overlap, and so before geolocation, some apparent spatial discrepancies may be observed. This will be visually corrected through geolocation. (3) An overlap between ECOSTRESS scans results in a line overlap and repeating data. Additional information is available in section 3.2 of the User Guide. If using AppEEARS or the swath2grid.py script to reproject the swath data, you still may see artifacts due to nearest neighbor resampling.
Why are there small patches of missing data?
Data are transferred in “packets”, which represent data bundles. Occasionally, a single packet is corrupted as it is transferred from the instrument to the ground data system.
Sometimes there are obstructions in the image, what is this?
Occasionally the ISS must adjust the position of some of its solar panel arrays. These may pass into the ECOSTRESS field of view.
Can I use ECO1BGEO files with corresponding Level 1B - Level 4 files if the build ID and/or product version number differ?
Yes, ECO1BGEO files are not reprocessed unless necessary and thus they may have a build ID and/or product version number different from corresponding Level 1B radiance or higher-level products.
Why do some waterbodies appear to be warmer than land?
Some images taken during nighttime can show higher temperature over waterbodies than surrounding land surfaces and images taken during daytime show lower temperature than surrounding land surfaces.
EMIT
What is imaging spectroscopy?
Imaging spectroscopy is a method of collecting imagery that acquires many bands of data over a large visible-shortwave infrared (VSWIR) spectral range with finer spectral resolution than traditional multispectral imaging. The EMIT instrument collects observations at 60-meter spatial resolution with a spectral range of 381 to 2493 nanometers (nm) across 285 bands with a spectral resolution of ~7.5 nm. The data produced through this method displays unique spectral signatures that can be used to identify materials more accurately, including the ten minerals of interest for the EMIT mission.
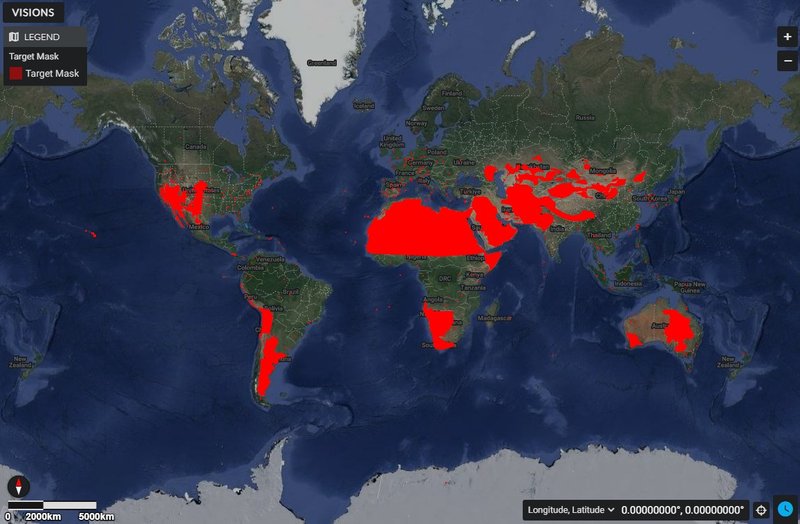
Why are there no EMIT observations over my specific study site?
EMIT’s main mission was to target various arid dust source regions across the globe between 52° N and 52° S latitudes as shown on the target mask map below. As the mission has progressed, some observations have been acquired outside of the original target mask area. Check out the EMIT Open Data Portal to see current and forecast coverage.
Why are there gaps in the EMIT observation record?
The EMIT mission launched on July 14, 2022, and after the in-orbit checkout period was successfully completed, first light images were captured over Australia on July 27, 2022. Full science quality data collection began August 9, 2022. However, beginning on September 13, 2022, a power issue outside of EMIT caused a pause in operations. Due to this shut down, no data were acquired from that date through January 6, 2023. Once the power issue was resolved, data collection operations resumed.
How do I orthorectify EMIT data granules?
EMIT data products delivered as Network Common Data Format 4 (netCDF4) files are provided in a spatially raw, non-orthocorrected format. Each netCDF4 file holds a location group containing geometric lookup tables (GLT), which are orthorectified images that provide relative x and y reference locations from the raw scene to allow for projection of the data. Along with the GLT layers, the files also contain latitude, longitude, and elevation layers. The latitude and longitude coordinates are presented using the World Geodetic System (WGS84) ellipsoid.
To help users access and work with EMIT data, the LP DAAC provides a GitHub repository containing various guides, short how-tos, and tutorials in the form of Jupyter Notebooks. These EMIT resources include a tutorial on How to Orthorectify EMIT data.
How does the EMIT mission support Open Science?
To help facilitate Open Science, all EMIT data are available publicly at no cost. The EMIT science team has also made the science data system code used to generate the data products publicly available. The code repositories are accessible through the emit-sds GitHub page. The programming languages include Python along with C++, R, Julia, and a few others. The EMIT team and the LP DAAC have also hosted workshops to showcase EMIT data and provide information on how to work with various data products. The LP DAAC also provides a number of guides, tutorials, and how-tos through GitHub.
Other than mineral mapping, what applications does EMIT data have?
While the main mission for EMIT is to map the surface mineralogy of arid dust source regions, there are various active and potential applications for EMIT data. Active applications include mapping greenhouse gases such as methane and carbon dioxide, and determining snow properties and water resources. Some potential applications include natural hazard detection, monitoring of crop health and agricultural production, forest management and fire-related mapping, and many more. With its wide coverage of the visible to shortwave infrared spectrum, the data produced by EMIT already have many applications, and new applications for this data will undoubtedly continue to arise.
Why are there black rectangular segments that stretch across some scenes?
The EMIT instrument has conservative on-board cloud filtering, which omits those portions of an affected scene when it is downlinked from the International Space Station (ISS). Due to the omission of those regions in the downlinked data, no information is delivered and thus not available for analysis.
Why are there obstructions blocking some images?
Occasionally the ISS must adjust the position of its solar panel arrays, which may pass into the EMIT field of view.
GEDI
Why do GEDI elevation values over my region of interest not match elevation values from another digital elevation model (DEM)?
A known ranging issue affects the absolute elevations of two of the eight beams (Beam0000 and Beam0001). Users are encouraged to read Section 3.7 of the ATBD for GEDI Waveform Geolocation for L1 and L2 products to fully understand the application of geophysical corrections. See Sections 6 and 8 of the Level 1 User Guide for a full description of quality and known issues. Section 6 of the Level 2 User Guide also provides important quality filtering information to ensure the elevation values are not affected by erroneous and/or lower quality returns, and Section 8 provides known issues..
How are GEDI beams split and dithered and what do these two terms mean?
Two of the GEDI lasers are full power, and the third is split into two beams, producing a total of four beams. Beam Dithering Units (BDUs) rapidly change the deflection of the outgoing laser beams. This produces eight ground tracks: four power and four cover tracks. Footprints are separated by 60 m along track and 600 m across track.
How should I quality filter GEDI L1B - L2B data?
Although all L2A and L2B algorithm results are available for every shot with a valid waveform, the science team recommends the following guidelines for selecting “best” data:
GEDI coverage beams (beams 0000, 0001, 0010, and 0011) were designed to penetrate canopies of up to 95% canopy cover under “average” conditions. For this reason, it is recommended to preference the GEDI full power beams in cases of dense vegetation. Second, nighttime GEDI data (solar_elevation < 0) is recommended over daytime acquisitions due to the negative impact of background solar illumination. It is then recommended to use the quality_flag dataset to remove erroneous and/or lower quality returns. For example, a quality_flag value of 1 will indicate that the shot meets criteria based on energy, sensitivity, amplitude, and real-time surface tracking quality.
How do I subset GEDI data spatially and by band/layer?
The LP DAAC has developed a data prep script called the GEDI Spatial and Band/layer Subsetting and Export to GeoJSON (GEDI Subsetter) script. The GEDI Subsetter is a command line executable python script that allows users to spatially subset GEDI files by submitting a GeoJSON or bounding box (Upper Left, Lower Right) region of interest. Users can also perform layer subsetting by defining specific GEDI datasets to be included in their subset output. The script will extract the desired layers, clip to the region of interest, and export as a GeoJSON file of points (shots) that can easily be loaded into GIS and/or Remote Sensing software for further visualization and analysis.
To access the GEDI Subsetter and for additional information on how to use it, visit: https://git.earthdata.nasa.gov/projects/LPDUR/repos/gedi-subsetter/browse.
How do I cite the data?
The following citation information is applicable for the GEDI01_B.002, GEDI02_A.002, and GEDI02_B.002 products:
Dubayah, R., Luthcke, S., J. B. Blair, Hofton, M., Armston, J., Tang, H. (2021). GEDI L1B Geolocated Waveform Data Global Footprint Level V002 [Data set]. NASA EOSDIS Land Processes DAAC. Accessed YYYY-MM-DD from https://doi.org/10.5067/GEDI/GEDI01_B.002.
Dubayah, R., Hofton, M., J. B. Blair, Armston, J., Tang, H., Luthcke, S. (2021). GEDI L2A Elevation and Height Metrics Data Global Footprint Level V002 [Data set]. NASA EOSDIS Land Processes DAAC. Accessed YYYY-MM-DD from https://doi.org/10.5067/GEDI/GEDI02_A.002.
Dubayah, R., Tang, H., Armston, J., Luthcke, S., Hofton, M., J. B. Blair (2021). GEDI L2B Canopy Cover and Vertical Profile Metrics Data Global Footprint Level V002 [Data set]. NASA EOSDIS Land Processes DAAC. Accessed YYYY-MM-DD from https://doi.org/10.5067/GEDI/GEDI02_B.002.
What science datasets does the GEDI Geolocated Waveforms product contain?
The L1B product provides corrected geolocated waveform returns, including transmit and receive housekeeping and relevant instrument parameters, as well as geolocation parameters and geophysical corrections. The detailed product contents are defined in the GEDI L1B Product Data Dictionary.
What science datasets does the GEDI Level 2A product contain?
The L2A product contains information derived from the geolocated GEDI return waveforms, including ground elevation, highest and lowest surface return elevations, energy quantile heights (“relative height” metrics), and other waveform-derived metrics describing the intercepted surface. The detailed product contents are defined in the GEDI L2A Product Data Dictionary.
What science datasets does the Global Ecosystem Dynamics Investigation Level 2B product contain?
The L2B product contains biophysical information derived from the geolocated GEDI return waveforms, including total and vertical profiles of canopy cover and Plant Area Index (PAI), the vertical Plant Area Volume Density (PAVD) profile, and Foliage Height Diversity (FHD). The detailed product contents are defined in the GEDI L2B Product Data Dictionary.
Why is the uneven spacing between beams across track?
While the design of the instrument and its operational implementation are to provide even cross-track spacing of the beams, several factors cause the beams to have small differences in the cross-track spacing. These factors include slight variations in beam alignment in the instrument frame, changes in altitude of the ISS, and changes in ISS attitude orientation, specifically yaw.
How do I extract elevation and height metrics for alternative algorithm setting groups in L2A?
Only the suggested result for each laser footprint is stored in the root group of the L2A product for each beam. This is currently set to the output of algorithm setting group 1 (see Table 5 of the Level 2 User Guide) and will be updated as post-launch cal/val progresses. Elevation and height metrics outputs for all algorithm setting groups can be found in the geolocation subgroup of the L2A data product. For example, elev_lowestreturn_a<n> is the elevation of lowest return detected using algorithm setting group <n>, relative to reference ellipsoid; and rh_a<n> are the relative height metrics at 1% intervals using algorithm <n> (in cm). See Section 5 of the ATBD for GEDI Waveform Geolocation for L1 and L2 Products for additional details.
How do I extract cover and vertical profile metrics for alternative algorithm setting groups in L2B?
Only the suggested result for each laser footprint is stored in the root group of the L2B product for each beam. The suggested result corresponds to the L2A algorithm setting group set in /BEAMXXX/selected_l2a_algorithm and will be updated as post-launch cal/val progresses. In contrast to the L2A data, only a select set of L2B algorithm outputs is stored for each L2A algorithm setting group. These outputs can be found in the /BEAMXXXX/rx_processing subgroup and include the directional gap probability (pgap_theta_a<n>), canopy (rv_a<n>) and ground (rg_a<n>) waveform integrals, and the results of the extended Gaussian fit, fit to the ground waveform (rg_eg_*_a<n>), where <n> is the algorithm setting group <n> (see Table 5 of the Level 2 User Guide). These outputs enable rapid recalculation of L2B vertical profiles for different L2A algorithm setting groups. Examples of this recalculation are being prepared by the GEDI Science Team as Python Jupyter Notebooks.
In L2A, why are Relative Height (RH) values sometimes negative?
Relative Height is calculated by the following equation: elev_highestreturn - elev_lowestmode. The lower RH metrics (e.g., RH10) will often have negative values, particularly in low canopy cover conditions. This is because a relatively high fraction of the waveform energy is from the ground and below elev_lowestmode. For example, if the ground return contains 30% of the energy, then RH1 through 15 are likely to be below 0 since half of the ground energy from the ground return is below the center of the ground return, which is used to determine the mean ground elevation in the footprint (elev_lowestmode). The RH metrics are intended for vegetated surfaces. Results over bare/water surfaces are still valid but may present some confusing results. See Section 6 Level 2 User Guide for more detailed information.
Is GEDI still an active instrument?
As of March 2023, the GEDI instrument has paused acquisition of science data for a period of 13 to 18 months in anticipation of its move to an alternate location on the International Space Station (ISS).
The ISS offers a unique hosting opportunity for Earth science payloads where NASA can test new instrument approaches that can make major contributions to understanding the changing planet.
NASA’s GEDI instrument aboard the space station is one of multiple instruments from the agency and others providing information about the Earth system and effects of climate change.
Demand is high for external operations on station, and GEDI is scheduled to be replaced by a Department of Defense (DOD) payload after more than four years of operations. However, the agency is exploring an option to keep the instrument in space through the life of the space station.
The proposed solution calls for temporarily moving GEDI to an alternate location, where it will remain offline while a DOD’s technology payload completes its mission. In 2024, GEDI will return to its original location, and resume operations on station.
What format does GEDI data come in?
The Level 1 and Level 2 GEDI datasets that are distributed by the LP DAAC are available as HDF5 (.h5). ORNL DAAC also distributes Level 3 and Level 4 GEDI datasets. The Level 3 and Level 4B datasets are gridded Tiff (.tif) and the L4A are HDF5 (.h5). Third party tools with HDF5 support include IDL and Matlab.
The LP DAAC also provides several Data Prep Scripts and Tutorials for GEDI data that you might be interested in. Please visit https://github.com/nasa/GEDI-Data-Resources to learn more.
Asking additional GEDI questions?
Have other GEDI questions? GEDI scientists can respond directly to your questions through the NASA Earthdata forum.
NASADEM
How is NASADEM different from SRTM?
Although NASADEM is derived from Shuttle Radar Topography Mission (SRTM) raw data, one of the primary differences is the use of the latest unwrapping technique and the reliance of auxiliary data to process the raw data, which were not available during the original SRTM processing. Due to an updated unwrapping technique, the results yield fewer voids in the mountainous regions as well as near the peripheral region of the spatial extent. Additional differences can be found on the DEM Comparison Guide.
What is the NASADEM Filename convention?
Each tile covers 1° latitude by 1° longitude of Earth’s surface. Let’s use NASADEM_HGT_n36w112 as an example. The first and second letters, in this case n and w respectively, cover the four corners of Earth’s surface (North, South, East, West). Therefore, n36 covers latitude 36 to 37 North and w112 covers longitude 112 to 113 West. The HGT extension stands for height or elevation.
Does NASADEM have restrictions on reuse, sale, or redistribution?
NASADEM does not have restrictions on reuse, sale, or redistribution. However, users of NASADEM products are encouraged to cite the product. A Citation Generator is available on each NASADEM DOI Landing Page.
Is there a method to download NASADEM data in bulk?
There are multiple methods to download NASADEM in bulk, such as Data Pool, OPeNDAP, and DAAC2Disk, which are all available at the LP DAAC Tools page.
Why can’t I view some NASADEM layers?
NASADEM has five data products, each with a different number of science data layers. The primary data product is the NASADEM_HGT, an elevation data product, which can be displayed in open source as well as commercial geospatial or visualization software. However, some of the auxiliary data layers are binary files; therefore, they must be imported manually to the software.
HLS
What is the difference between the L30 and the S30 product?
Harmonized Landsat Sentinel-2 (HLS) uses a processing chain involving several separate radiometric and geometric adjustments, with a goal of eliminating differences in retrieved surface reflectance arising solely from differences in instrumentation. Input data products from Landsat 8 and Landsat 9 (Collection 2 Level 1T top-of-atmosphere reflectance or top-of-atmosphere apparent temperature) and Sentinel-2A and Sentinel-2B (L1C top-of-atmosphere reflectance) are ingested for HLS processing. A series of radiometric and geometric corrections are applied to convert data to surface reflectance, adjust for BRDF differences, and adjust for spectral bandpass differences in section 3.1 of the Algorithm Theoretical Basis Document.
Two types of products are then generated: HLSS30 and HLSL30 (colloquially referred to as S30 and L30, respectively).
S30 and L30 tiles are produced in the Universal Transverse Mercator (UTM) projection and map to the UTM-based Military Grid Reference System (MGRS), which is currently used by Sentinel-2. Each tile is approximately 110 x 110 kilometers with a 30 meter (m) spatial resolution.
LP DAAC distributes both the S30 and L30 products:
- S30: Multi-Spectral Instrument (MSI) harmonized surface reflectance resampled to 30 m into the Sentinel-2 tiling system and adjusted to the Landsat 8/9 spectral response function.
- L30: Operational Land Imager (OLI) harmonized surface reflectance and Top-of-Atmosphere (TOA) brightness temperature, resampled to 30 m, into the Sentinel-2 tiling system.
What is the difference between the version 1.4 and 2.0 products?
HLS v2.0 builds on v1.4 by updating and improving processing algorithms, expanding spatial coverage, and providing validation. Particular updates are as follows:
− Global coverage. All global land, including major islands but excluding Antarctica, is covered.
− Input data Landsat 8/9 Collection 2 (C2) data from USGS are used as input; better geolocation is expected as C2 data use the Sentinel-2 Global Reference Image (GRI) as an absolute reference.
− Atmospheric correction. A USGS C version of LaSRCv3.5.5 is applied for both Landsat 8/9 and Sentinel-2 data for computational speedup. LaSRCv3.5.5 has been validated for both Landsat 8/9 and Sentinel-2 within the CEOS ACIX-I (Atmospheric Correction Inter-Comparison eXercise,
http://calvalportal.ceos.org/projects/acix).
− Quality Assurance band. The QA band is generated exclusively by, and named after, Fmask for both S30 and L30. Like in v1.4, aerosol thickness level from atmospheric correction is also incorporated into the QA band.
− BRDF adjustment. BRDF adjustment mainly normalizes the view angle effect, with the sun zenith angle largely intact. This adjustment is applied to the Sentinel-2 red-edge bands as well.
− Sun and view angle bands are provided.
− Product format. Each band in each product is delivered as individual Cloud Optimized GeoTIFF (COG) files.
− Temporal Coverage and Latency in v2.0 moves toward “keep up” processing. The intent is to continually update products with 2-4 day latency.
− HLS v2.0 provides Landsat and Sentinel-2 data products at 30 m spatial resolution. HLS v1.4 provided Sentinel-2 data at 10 meter resolution.
What is the difference between HLS granules and files? Also, what is a Cloud Optimized GeoTIFF (COG)?
Harmonized Landsat Sentinel-2 (HLS) products are produced and distributed from the Earthdata Cloud as Cloud Optimized GeoTIFF (COG). HLS granules refer to a group of files produced for an individual tile for a specific date and time. The files produced for each granule include COGs for each surface reflectance band and associated quality layer(s), as well as associated metadata files.
In every practical sense, COGs are regular GeoTIFF files. COGs are set apart from regular GeoTIFF files by the internal organization of the COG, which provides an efficient way of accessing pieces of a file rather than downloading the entire contents of a file. This is leveraged by clients that have the ability to issue HTTP GET range requests.
What are the criteria for selecting acceptable Sentinel-2 Tiles for HLSS30 v2.0 processing?
HLS images are processed if the following criteria is met:
− There’s a minimum solar zenith angle of 76 degrees (this mainly cuts out areas to the far north in winter).
− Cloud cover less than 95%.
G-LiHT
Why did NASA scientists develop G-LiHT?
Merging of time-series and multi-sensor image data is a fusion process that allows scientists to study interactions between ecosystem composition, structure, and function. Equipped with this knowledge, we can better predict ecosystem responses due to land use, disturbance, and climate change.
Goddard's LiDAR, Hyperspectral, and Thermal Airborne Imager (G-LiHT) enables data fusion studies by providing coincident data in time and space, providing fine-scale (<1 m) observations over large areas that are needed for regional ecosystem studies. Mutli-sensor G-LiHT data solves a longstanding problem in data fusion studies—coregistration and analysis of data acquired at different seasons and illumination conditions, and often at different spatial resolutions.
G-LiHT lidar, passive, optical, and thermal data provide an analytical framework for the development of new algorithms to map plant species composition, plant functional types, biodiversity, biomass and carbon stocks, and plant growth. G-LiHT data are also used to initialize and validate 3-dimensional radiative transfer models, and intercalibrate Earth observing satellites.
G-LiHT was specifically designed for use with a wide range of common, general aviation aircraft in order to provide affordable, well-calibrated image data worldwide.
How intercomparable are G-LiHT acquisitions and data products?
G-LiHT data are typically acquired with the same instrument settings and flight parameters (e.g., flying altitude, and speed); however, users are strongly encouraged to refer to the metadata and ancillary data layers for specific acquisition details. G-LiHT data are acquired for specific science applications and differences between campaigns will partially reflect the different strategies for data acquisition to support the science efforts.
G-LiHT data are acquired below clouds at a nominal altitude of 335 meter (m) during various times of day and sky conditions. As a result, artifacts associated with cloud shadows and variable illumination conditions may appear in the passive optical data products, particularly on days with intermittent cloud cover.
How is G-LiHT calibrated?
Radiometric calibration and spectral characterization of G-LiHT's imaging spectrometer is performed at NASA Goddard Space Flight Center, using a tunable laser light source and Spectral Irradiance and Radiance Responsivity Calibrations using Uniform Sources (SIRCUS), a system that maintains National Institute of Standards and Technology (NIST)-traceability via transfer radiometers.
G-LiHT lidar and thermal instruments are factory calibrated.
Lidar apparent reflectance (fraction of outgoing pulse energy in a given return) is factory calibrated and corrected for ranging distance, but not for scan angle or atmospheric interactions.
How is the at-sensor reflectance product computed?
At-sensor reflectance is computed as the ratio between observed upwelling radiance and downwelling hemispheric irradiance. An empirically derived multiplier is used to correct for differences in cross-track illumination and Bidirectional Reflectance Distribution Function (BRDF).
How do I cite G-LiHT data in a paper?
Please cite G-LiHT data products in the following format:
Cook, Bruce. GLCHMT: G-LiHT Canopy Height Model Mosaic V001. 2020, distributed by NASA EOSDIS Land Processes DAAC, https://doi.org/10.5067/Community/GLIHT/GLCHMT.001. Accessed YYYY-MM-DD.
NASA's Earth Science Program promotes the full and open sharing of data with all users, in accordance with NASA's Data and Information Policy.
G-LiHT scientists are willing collaborators who will be able to share their scientific expertise, first-hand knowledge of the acquisitions, and unique insight on the interpretation of these data.
Please notify the LP DAAC of publications and presentations citing G-LiHT so that they can be added to the growing list of G-LiHT citations.
Can I request G-LiHT data acquisitions for a specific study site?
G-LiHT is a Principal Investigator-lead instrument that was designed, assembled, maintained, and flown using funds from competed research grants. The G-LiHT team is constantly proposing and acquiring new acquisitions, motivated by NASA's Earth Science mission to understand the changing climate, its interaction with life, and how human activities affect the environment.
Please contact the LP DAAC or the G-LiHT team with compelling science questions or geographic targets of opportunity that G-LiHT could address in a future science proposal.
Why do some Digital Surface Model (DSM) granules contain only three science data layers while others contain five?
Not all campaigns and flights included production of a Digital Surface Model (DSM) data product. DSM Rugosity, Aspect, and Slope are derivatives of the Canopy Height Model (CHM) and Digital Terrain Model (DTM) products which were generated for most study areas. Some flights contain only those Rugosity, Aspect, and Slope data, while others also include DSM and DSM Mean. When released, the G-LiHT Flight Metadata (GLMETA) dataset will provide detailed information on the configuration of the G-LiHT sensor for each flight.
How do I view the data in the Hyperspectral datasets (GLREFL, GLRADS, GLHYVI, GLHYANC)?
Hyperspectral datasets function similarly to a GeoTIFF, but are delivered to the user as a compressed zip file (.zip). After this file is extracted, there are two individual files. The first is a file with no extension. The second is a .hdr, or header, file. The header file is required, as it contains metadata for ENVI-format images. It is recommended that users load hyperspectral data into ENVI, although data can also be loaded into other geographic information systems through either menu options or a direct drag-and-drop.
Data Access
How can I bulk download data distributed by the LP DAAC?
Bulk download options are available from DAAC2Disk as a script that can be downloaded and executed from the command line. Also, data are available from the LP DAAC Data Pool via HTTPS. Please ensure you have authorized your download method for your Earthdata login account. To accomplish this, log in to your account from the Earthdata Login page, and click on “ Authorized Apps” under "Applications" in the title bar. You will be presented with a list of approved applications. At the bottom of the list click the “Approve More Applications” button. Type in “LP DAAC Data Pool” in the text box and hit enter. In the application search results click the checkbox next to “LP DAAC Data Pool” and then click the “Approve” button. You should be returned to the approved applications page with a green confirmation bar acknowledging your request. Be sure to update your scripts to allow for logging in to your Earthdata login account.
Where is my data order notification?
Typically you will receive a notification that your order was submitted within a few minutes. However, if your order was placed more than 3 days ago and you still have not received a notification from us, please check your spam folder. Also, please add "lpdaac@usgs.gov" to your list of trusted senders to prevent notifications from going to Spam folder in the future. If you have checked your Spam folder and did not receive a notification, please contact LP DAAC User Services at lpdaac@usgs.gov.
What is an Earthdata account and how can I create one?
An Earthdata Login account provides a single access point for user registration and profile to manage all EOSDIS system components (DAACs, Tools, and Services). Your Earthdata Login account helps the EOSDIS program understand how users are using EOSDIS services and this aids in helping improve the user experience through improvements to tool customization and services. The Earthdata Login account is available at no charge to the user and provides open access to EOSDIS data free of charge
Data Citation and Reuse
How do I cite my data?
Each DOI Landing Page provides a citation generator that will automatically create a citation for you based on the data product you are using. The DOI Landing Pages can be found under the search data catalog.
Am I allowed to reuse LP DAAC data?
All data distributed by the LP DAAC contain no restrictions on the data reuse.